Task 1: Query Suggestion
Objective:
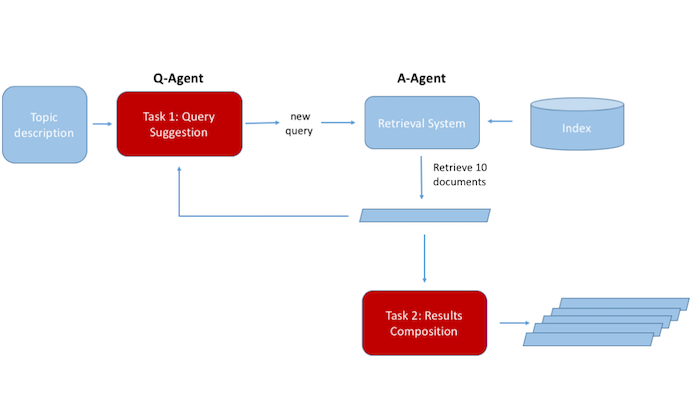
Given a verbose description of a task (topic) generate a sequence of queries and their corresponding rankings of the collection.
Submission Guidelines:
Each Q-Agent is allowed to go over 10 rounds of query suggestions. At each round one query is submitted to the A-Agent, and the top 10 results are collected. At the end of round 10, 100 search results will have been collected.
Submission Format:
The lab will use TREC-style submissions. In TREC, a "run" is the output of a search system over ALL topics. Run Format:
| TOPIC |
QUESTION |
DOCNO |
RANK |
SCORE |
RUN |
- TOPIC is the topic id and can be found in the released topics
- QUESTION is the suggested query of this round. The question should be included into quotes, e.g. "london hotels". Each suggested query should be repeated over a maximum of 10 rows (i.e. for each one of the top 10 results obtained by submitting this query to the A-Agent.
- DOCNO is the document number in the corpus
- RANK is the rank of the document returned for this given round (in increasing order)
- SCORE is the score of the ranking/classification algorith
- RUN is an identifier/name for the system producing the run
Evaluation:
The measurements of runs are Cube Test, sDCG and Expected Utility; other diagnostic measures such as precision and recall may also be reported.
Cube Test is a search effectiveness measurement evaluating the speed of gaining relevant information (could be documents or passages) in a dynamic search process. It measures the amount of relevant information a system could gather and the time needed in the entire search process. The higher the Cube Test score, the better the IR system.
sDCG extends the classic DCG to a search session which consists of multiple iterations. The relevance scores of results that are ranked lower or returned in later iterations get more discounts. The discounted cumulative relevance score is the final results of this metric.
Expected Utility scores different runs by measuring the relevant information a system found and the length of documents. The relevance scores of documents are discounted based on ranking order and novelty. The document length is discounted only based on ranking position. The difference between the cumulative relevance score and the aggregated document length is the final score of each run.